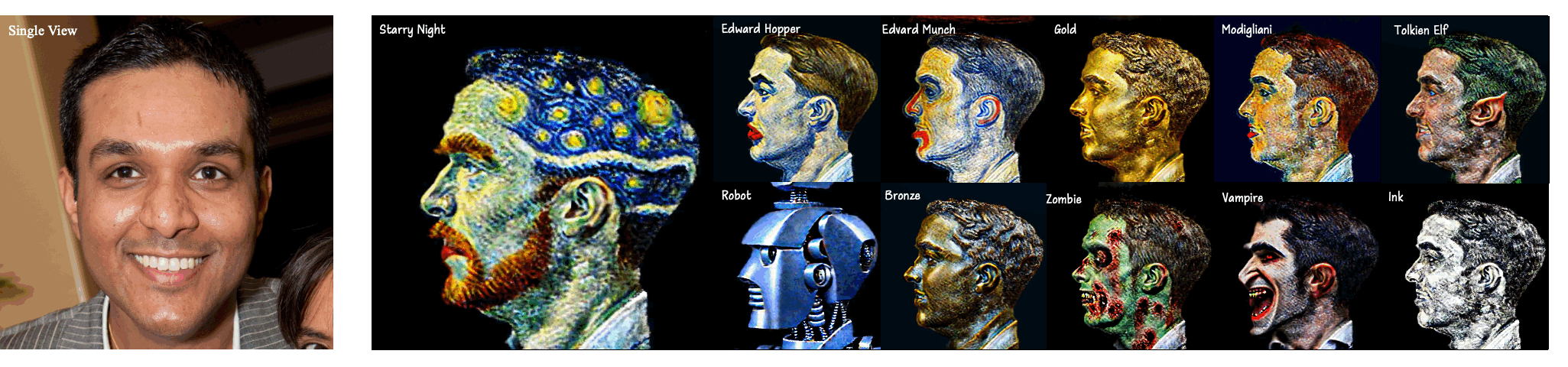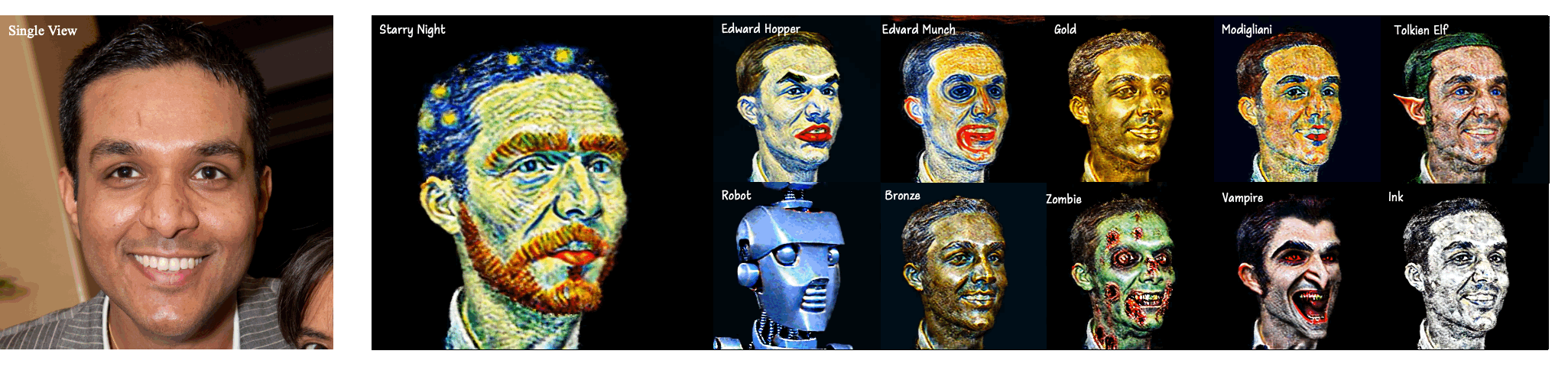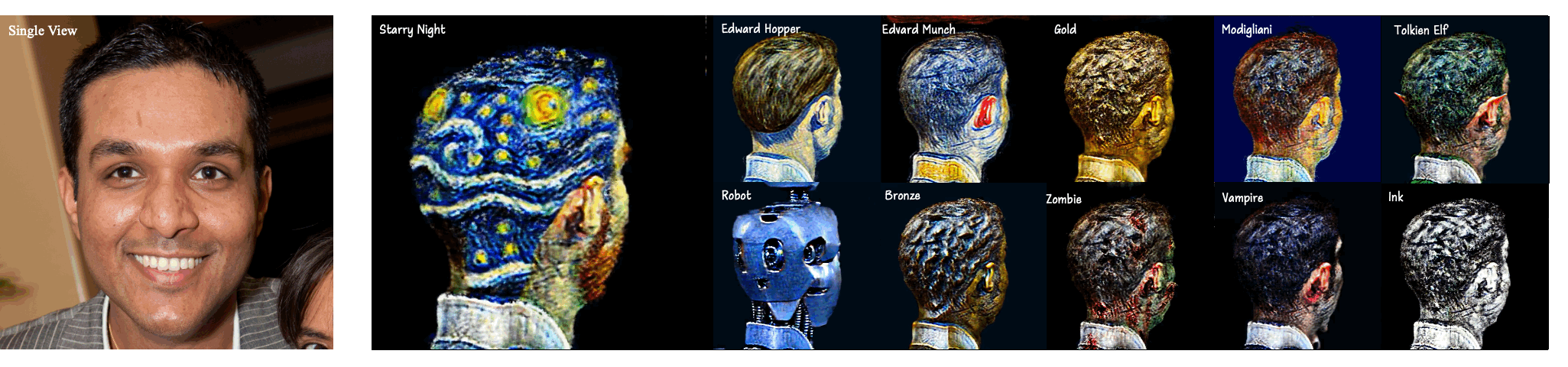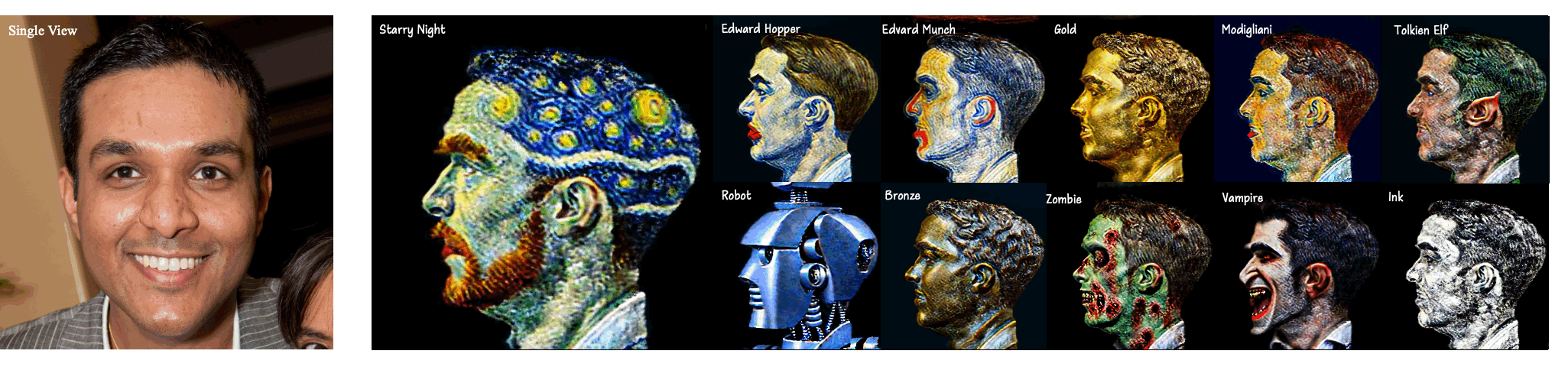
In this paper, we investigate a practical One-to-Style task that generates the 3D style avatar with a single view. The task presents two challenges: 1) Content consistency and 2) Style consistency across multiple views of the 3D style avatar. We propose StyleDreamer to address the two problems. For the first problem, our StyleDreamer employs a 3D GAN to preserve the identity of each view. For the second problem, we propose a novel Multi-View Consistency Score Distillation (MV-CSD) to ensure performing consistent stylization across multiple views. In this way, the style of the rendered images from all views is supervised to match the style of the given view, based on the provided edit instruction. Experimental results show that our approach outperforms existing methods in terms of stability and quality, indicating its potential applications in the real world.
StyleDreamer:
Our method generates a 3D head avatar whose content and style are consistent with the given portrait image and style prompts, respectively.




